خرید یک کامپیوتر یادگیری عمیق - David v.s. Goliath
خرید یک کامپیوتر یادگیری عمیق - David v.s. Goliath

MVP در دنیای فناوری نیست " با ارزش ترین بازیکن ”. حداقل محصول پایدار (MVP) به معنای آزمایش فرضیه ها ، یافتن تناسب بازار محصول مطلوب و انجام آنچه اهمیت دارد ، می باشد. به عبارت دیگر ، بیش از حد برنامه ریزی نکنید ، از تجربه خود درس بگیرید و راه حل را مقیاس بندی کنید.
من ارتقاء رایانه شخصی Deep Learning شخصی خود را در 12 ماه گذشته به تعویق انداخته ام. من منتظر زمان مناسب برای ساخت MVP جدید 2020 هستم. در این مقاله ، ما در مورد نکات کلیدی تصمیم گیری و هزینه های خرید رایانه Deep Learning (DL) بحث خواهیم کرد. همچنین ، ما جایگزین هایی مانند راه حل ابری را بررسی خواهیم کرد. اما برای افرادی که فقط یک پاسخ سریع می خواهند ، در انتهای مقاله خواهد بود.
وقتی خانه جدیدی میلیون دلاری می سازید ، ممکن است برای یک خانه 850 هزار دلاری با بقیه برنامه ریزی کنید. صندوق احتمالی یکبار کلاس مدیریت UCLA روش دیگری را به من آموخت. یک خانه 1.2 میلیون دلاری طراحی کنید و تلاش کنید تا مبلغ یک طرح را به مبلغ 1 میلیون دلار بپردازید. بنابراین ، بیایید ابتدا به وضعیت ماشین مدرن نگاه کنیم.
 منبع DGX SuperPod
منبع DGX SuperPod انویدیا یک دستگاه جالب به نام DGX SuperPod دارد. دارای 96 سیستم DGX-2H با مجموع 192 CPU ، 1536 GPU و حافظه GPU 1.4 TB است. این دستگاه یک مدل بسیار مهم NLP (BERT-large) را در 47 دقیقه آموزش می دهد. در غیر این صورت یک ماه سیستم GPU طول می کشد.
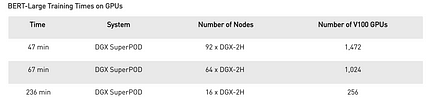 منبع < p> این سیستم شامل 96 غلاف DGX-2 است. هزینه هر غلاف با 16 GPU Nvidia Tesla V100 حدود 400 هزار دلار است. آیا این می تواند طرح میلیون دلاری من باشد؟ این بازی David vs vs. داستان جالوت.
منبع < p> این سیستم شامل 96 غلاف DGX-2 است. هزینه هر غلاف با 16 GPU Nvidia Tesla V100 حدود 400 هزار دلار است. آیا این می تواند طرح میلیون دلاری من باشد؟ این بازی David vs vs. داستان جالوت. انتخاب های دیگر چیست؟
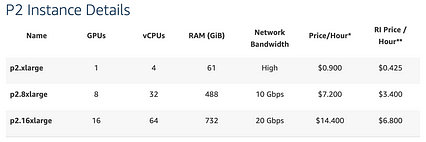
اگر هیچ وقت دوره DL را گذرانده اید ، فقط برای انجام کدنویسی DL دستگاه جدیدی نخرید. اولین کد DL شما باید در Google Colaboratory یا یک دستگاه بازی که قبلاً داشتید باشد. برای پروژه نهایی یا ارائه پوستر ، احتمالاً به چیزی قوی تر نیاز دارید. اگر کارت گرافیک Nvidia ندارید ، راه حل ابری جایگزین خوبی است. اولین احتمال آمازون AWS است. نمودار زیر قیمت دستگاه مبتدی با GPU است. آموزش مدل با GPU K80 برای چند روز 43 دلار هزینه دارد.
 منبع: Amazon AWS
منبع: Amazon AWS خوشبختانه آمازون نمونه ای را ارائه می دهد که تقریباً 1/3 قیمت بالا است.

نتیجه این است که آمازون می تواند نمونه شما (سیستم مجازی) را در هر زمان در زمان تقاضای زیاد از بین ببرد. با ذخیره سازی EBS و تغییر ساده کد DL ، می توانید به صورت دستی آموزش را در یک نمونه جدید به راحتی بازیابی و از سر بگیرید. خوشبختانه ، این اغلب اتفاق نمی افتد. قیمت نمونه با GPU های بیشتر به سرعت افزایش می یابد. اما با مدلهای پیچیده ای که نیاز به آموزش GPU های زیاد دارند ، این یک راه حل عالی است.
یک جایگزین ابری جدید Google Cloud TPU است.
 منبع
منبعیکبار معیارهای عملکرد Google TPU (واحد پردازش تنسور) را بررسی کردم. وقتی عملکرد غیر معمول را در مدل Transformer می بینم ، واضح است که TPU در عملکرد ماتریس تخصص دارد. از نظر ریاضی ، Tensor یک مقیاس مقیاس پذیر یا k-D است. به همین دلیل است که پردازنده TPU نامیده می شود. این استپردازنده ای که در عملیات ماتریسی برای جبر خطی تخصص دارد. ما می توانیم توسعه را با یک کامپیوتر مستقل با GPU (ها) شروع کنیم. سپس در صورت نیاز می توانیم برای آموزش گسترده تر به محاسبات ابری برویم.
هشدار
همه اطلاعات قیمت ، عملکرد و مدل در اینجا فقط یک تصویر فوری است. هدف از این مقاله این است که اطلاعات کافی در اختیار شما قرار دهد تا در خریدهای بعدی راهنمای شما باشد.
چه سیستمی بخرم؟
شخصاً ، من از یک سیستم مستقل برای توسعه و استفاده استفاده می کنم راه حل های ابری برای آموزش مدلهای بسیار پیچیده اما هزینه می تواند به سرعت افزایش یابد. بنابراین ، بگذارید فعلاً بر خرید یک کامپیوتر DL تمرکز کنیم. اما هیچ توصیه خوبی نمی تواند بدون زمینه مناسب ارائه شود.
بنابراین من در پاسخ به این س approachال روش دیگری را امتحان می کنم. در بخش قبل ، من مورد مبتدیان را با گزینه های رایگان و دامنه های بسیار سخت با استفاده از محاسبات ابری پوشش می دهم. در بقیه موارد ، من تقریباً روی 5 محدوده قیمت برای کل رایانه تمرکز می کنم و بحث می کنم که با آن چه کاری می توانید انجام دهید.
زیر 1000 دلار
برای افرادی که دارای کارت گرافیک GPU هستند 4 تا 6 گیگابایت ، شما می توانید تکالیف دوره DL را تکمیل کنید. من این را در محدوده رایانه زیر 1000 دلار طبقه بندی می کنم. برای پیش بینی می توانید از بسیاری از مدل های معروف مانند ResNet 50 استفاده کنید. با این حال ، شما نمی توانید آنها را بدون ساده سازی قابل ملاحظه یا از دست دادن دقت اعتبارسنجی مجدد آموزش دهید یا اصلاح کنید. شما می خواهید پروژه ای را به پایان برسانید که بتواند مردم را در یک ارائه پوستر مجذوب کند. ممکن است آموزش مدل های شما زیاد طول بکشد و شما می خواهید بیشتر یا همه آزمایشها را به ماشینهای محلی منتقل کنید. این محدوده دستگاه گیمینگ 1700 دلار است که ممکن است به آن توجه کنید. برای این سطح ، می توانید یک CPU خوب ، 32 گیگابایت RAM ، یک پردازنده گرافیکی با 8 گیگابایت حافظه و 2 تا 3 ترابایت حافظه دریافت کنید. 700 دلار دیگر می تواند Nvidia 2080TI را با 11 گیگابایت حافظه GPU به شما تحویل دهد. وقتی از 2070 به 2080TI حرکت می کنید ، عملکرد تقریباً 100 افزایش می یابد.
بیایید کمی ریاضی انجام دهیم تا ببینیم در این مدل پیشرفته 2080 TI در مدل صنعتی DL چه می توانید انجام دهید. ResNet 50 در بینایی رایانه ای بسیار محبوب است. در مجموع دارای 23،587،712 پارامتر است. برای هر نمونه ، حدود 16 میلیون فعال سازی وجود دارد که باید در گذر جلو برای انجام انتشار عقب ثبت شود. در مقاله ResNet ، آزمایش از اندازه دسته ای 256 با مجموع 600000 تکرار استفاده کرده است. یعنی 153.6 میلیون تصویر پردازش شده است. یک پردازنده گرافیکی 2080TI می تواند در ResNet 50 294 تصویر در ثانیه اجرا کند (برای جزئیات به اعتبار مراجعه کنید). کل آموزش را می توان در 6 روز انجام داد. اما ، برای تناسب همه پارامترهای مدل و نتایج فعال سازی یک دسته در پردازنده گرافیکی 11 گیگابایتی ، ممکن است اندازه دسته را به 32 کاهش دهیم. خوشبختانه ، بهینه سازی با دقت مختلط آموزش (3.3x) را سرعت بخشیده و نیاز حافظه را کاهش می دهد. اما بعداً این بحث را به تأخیر می اندازیم. در حال حاضر ، باید احساس کنید که چه پولی می تواند برای شما خرید کند.
5400 دلار با GPU های دوگانه
در حال حاضر ، شما بسیار جدی هستیددر DL شما مدلهای جدیدی را توسعه می دهید و آموزش می دهید که نیاز به آزمایش های زیادی دارد. ممکن است صدها آزمایش قبل از یافتن آزمایش مناسب طول بکشد. شما تکرارهای سریع می خواهید و نمی توانید ساعت ها یا روزها منتظر بمانید تا بدانید حرکتهای بعدی چه باید باشند. می توانید کارت GPU دیگری را به دستگاه وصل کنید که از 500 دلار تا 1 هزار دلار بیشتر هزینه دارد. متأسفانه ، در برخی از پردازنده های گرافیکی پیشرفته ، ممکن است این کار نکند. فروشندگان عمده رایانه های شخصی ممکن است از شما بخواهند که ابتدا دستگاه را با منبع تغذیه بزرگتر ، CPU سطح بعدی و خطوط وسیع تر PCIe به سطح بعدی برسانید. به عنوان مثال ، یک رایانه دوگانه 2080TI با حافظه CPU 64G از یک فروشنده کامپیوتر حدود 5.4 هزار دلار هزینه خواهد داشت. که از یک دستگاه 2.580 دلاری تک 2080TI افزایش می یابد. اکنون ، شما شاهد افزایش قیمت غیر خطی با قابلیت سیستم هستید. خوشبختانه ، برای یک دستگاه دوگانه 2080 ، ممکن است هنوز بتوانید آن را حدود 2.5 هزار دلار دریافت کنید.
آیا هنگام افزودن کارت جدید ، عملکرد را دو برابر می کنید؟ پاسخ بستگی به مدلهای DL دارد اما خبر خوب این است که اکثر مدلها در این محدوده بسیار خوب مقیاس دارند. بسیاری از پلتفرم های نرم افزاری DL به گونه ای بهینه شده اند که برای بسیاری از مدلهای محبوب در این منطقه خطی مناسب باشند. چیزی که باید به آن توجه کنید ، مدل Transformer در NLP است. این مدل اساساً از لایه های کاملاً متصل تشکیل شده است. برای افزایش موازی سازی داده ها به تکنیک های بهینه سازی بیشتری نیاز است.
$ 8K+ با چندین GPU
ایده راه اندازی شگفت انگیزی دارید. اما نیاز به آموزش طولانی مدت با مدل های بزرگ DL دارد. اکنون ، شما در منطقه ای هستید که اکثر فروشندگان بزرگ رایانه شخصی محصولی برای شما ندارند. آن را از فروشگاه های تخصصی تهیه خواهید کرد. قیمت دستگاه 4x 2080TI حدود 8 هزار دلار است. بله ، اکثر مدلهای DL هنوز در این منطقه از مقیاس معقول خوبی برخوردارند. می توانید تا 4 برابر پیشرفت کنید.
فراتر و بالاتر
سطح بعدی برای شرکت ها و مراکز داده مورد هدف قرار می گیرد. این شامل GPU های سطح بالا در یک خوشه می شود. این ماشینها گران هستند. دستگاه موجود در AWS متعلق به این کلاس است. یک مزیت کلیدی میزان حافظه برای پردازنده گرافیکی است که احتمالاً 24 گیگابایت+ است و می توانید مدلی با پردازنده های گرافیکی متعدد آموزش دهید. برای اکثر مردم ، می توانیم از طریق سرویس ابری به این ماشین ها دسترسی پیدا کرده و ساعت ها آن را اجاره کنیم. به زودی ، حتی ممکن است یک ابررایانه 800 NVIDIA V100 Tensor Core GPU از Microsoft Azure اجاره دهیم.
چقدر هزینه کنیم؟
هنوز ممکن است بپرسید که چه محدوده قیمتی را باید هزینه کنید. برای کاربران متوسط تا پیشرفته ، ما می توانیم آنها را در دو گروه قرار دهیم: توسعه دهندگان برنامه که آموزش مدل پیچیده را انجام نمی دهند و محققان مدل. برای گروه قبلی ، آنها ممکن است از انتخاب مدلهای DL از پیش آموزش دیده و تمرکز بر ایجاد راه حل فقط از طریق پیش بینی ها-بدون هیچگونه آموزش پیچیده ای متمرکز شوند. از آنجا که بسیاری از سیستم عامل های نرم افزاری DL دارای باغ وحش از مدل های معروف هستند ، این مهندسان به خوبی تحت پوشش قرار گرفته اند. آنها می توانند با پردازنده های گرافیکی با حافظه کمتر کنار بیایند. در غیر این صورت ، برای آموزش مدلی با اندازه دسته ای K ، تقریباً K برابر منابع GPU نیاز است.
ما معمولاً ResNet یا VGG16 را آموزش نمی دهیم. اما اگرشما در حال حل یک حوزه مشکل با داده های آموزشی بسیار متفاوت هستید ، باید مدل را مجددا آموزش دهید. در شرایط دیگر ، شما مدلهای سفارشی ایجاد می کنید یا مدلهای از پیش آموزش دیده را با یادگیری انتقال بهینه می کنید. وقتی ResNet با 152 لایه معرفی شد ، برخی از مردم خندیدند. در حال حاضر ، مدل ها با لایه های عمیق در فضای نهفته با ابعاد بالا بسیار پیچیده شده اند. به طور خلاصه ، عملکرد GPU و حافظه مورد نیاز برای محققان مدل بسیار بیشتر از توسعه برنامه است.
زمان آزمایش روزانه شما چقدر است. اگر برخی از بازی های اصلی را نمی توان یک شبه به پایان رساند ، ممکن است لازم باشد بازی خود را کمی بیشتر ارتقا دهید. نحوه تکرار راه حل ها به شما آسیب می رساند و شانس موفقیت شما را به میزان قابل توجهی کاهش می دهد. باز هم ، پارامترهای متحرک بسیار زیادی در اینجا وجود دارد تا یک پیشنهاد کلی ارائه شود. به عنوان مثال ، متخصصان ممکن است برای زمان خود بیشتر از دانش آموزان ارزش قائل شوند و مایل به پرداخت هزینه بیشتر با بازده عملکرد کمتر باشند. > انتخاب اجزا
GPU
نسبت GPU به CPU در سیستم DGX-2H برابر 8: 1 است. رد شدن از اتصالات به ما امکان می دهد مدل هایی را در عمق بسیار بیشتری بسازیم. همانطور که انتظار داریم آموزش مدل مورد نظر ما محدود به GPU باشد ، اولویت اول ما انتخاب GPU خواهد بود.
کدام پردازنده DL را انتخاب می کنیم؟ GPU انویدیا از DL بهترین پشتیبانی را می کند. می توانید از سرویس ابری به Google TPU دسترسی پیدا کنید. اما شما نمی توانید TPU بخرید. طی چند سال گذشته ، AMD در زمینه پشتیبانی نرم افزار DL از جذابیت خوبی برخوردار است. استراتژی این است که از پلت فرم ROCm در تهیه دستگاه و محیط آگنوستیک نرم افزار استفاده کنید. یک ایده کلیدی استفاده از HIP (Heterogeneous-Computing Interface) برای سهولت تبدیل برنامه های Cuda به کد C ++ است. اما تبدیل تمام پایگاه های کد TensorFlow یا PyTorch به HIP ممکن است به ظاهر ساده به نظر نرسد. از آنجا که شیطان در جزئیات است ، ممکن است استراتژی کلی قبل از تبدیل شدن به یک جایگزین قانع کننده ، دو برابر شود. این خبر بسیار بدی برای کاربران Mac مانند من است. برای کاربران Mac ، ممکن است لازم باشد یک جعبه لینوکس جداگانه بسازید.
حافظه GPU یکی دیگر از نگرانی های اصلی است. ResNet 50 دارای پارامترهای مدل 24M است. برای انجام انتشار گرادیان عقب ، به حافظه نیاز دارد تا همه فعالسازی ها را در هر لایه برای هر نمونه آموزشی ذخیره کند. مدلهای ترانسفورماتور که در NLP رایج می شوند حافظه زیادی را می گیرند. حافظه یک مشکل در مشکلات NLP است زیرا عملکرد هزینه آنها دارای انحنای زیادی است و به اندازه دسته بزرگتری نیاز دارد. این چالش ممکن است توسط Google در اجرای BERT منبع باز خود در سال 2018 خلاصه شود. در حال حاضر امکان تولید مجدد اکثر نتایج BERT-Large روی کاغذ با استفاده از GPU با 12 گیگابایت-16 گیگابایت وجود نداردRAM ، زیرا حداکثر اندازه دسته ای که می تواند در حافظه جا بیفتد بسیار کوچک است. ما در حال کار روی افزودن کد به این مخزن هستیم که اجازه می دهد اندازه دسته ای بسیار بزرگتر در GPU باشد.
اما نیاز حافظه به شدت به اجرا بستگی دارد. بعداً ، NVidia دارای پیاده سازی است که مدل را با 16 گیگابایت آموزش می دهد. با این وجود ، روند افزایش نیاز به حافظه GPU به احتمال زیاد ادامه خواهد یافت. مغز انسان دارای 86 میلیارد سلول عصبی با 1000 تریلیون ارتباط سیناپسی است. حافظه GPU فعلی شاید درست مانند RAM 128K در اولین Apple Macintosh باشد. اما با قیمتی همراه است. قیمت دو برابر از 8 گیگابایت GPU (500-700 دلار) به 11 گیگابایت GPU (1100 دلار) و سپس دوباره تا 24 گیگابایت. بهبود عملکرد مربوطه مانند 100٪ از 2070 تا 2080TI ، 50٪ از 2080 تا 2080TI و 20٪ از 2080TI تا Titan RTX خواهد بود. اگر مفهوم DL مورد بحث خود را درک نمی کنید ، اگر می خواهید زمان خود را روی DL سرمایه گذاری کنید ، پردازنده گرافیکی 8 گیگابایتی (2070 super یا 2080 super) شروع خوبی است. بسیاری از مردم از پردازنده گرافیکی 11 گیگابایتی (2080TI) به دلیل سرعت آن استقبال می کنند. نکته اصلی فروش 24 گیگابایت این است که آیا می توانید مدل را تنها با 11 گیگابایت حافظه آموزش دهید. باز هم ، اگر اطلاعات DL را در اینجا نمی فهمید ، با اصل MVP همراه باشید. با این وجود ، این معیارهای عملکرد به شدت به آزمایشات و کدگذاری مربوطه بستگی دارد. این باید یک مرجع باشد و مسافت پیموده شده شما ممکن است به میزان قابل توجهی متفاوت باشد.
و این اطلاعات با قیمت گذاری به سرعت تغییر می کند. بسیاری از معیارهای عملکرد GPU خوب و تجزیه و تحلیل قیمت/عملکرد بصورت آنلاین وجود دارد. پیوندهای آنها را در قسمت مرجع دارم. چند دقیقه را در آنجا بگذرانید و تشخیص اعداد مورد نیاز سخت نباشد. در سالهای اخیر ، پیچیدگی مدل سریعتر از بهبود GPU رشد می کند. بنابراین ما می توانیم انتخاب را از نقطه قیمت به جای سرعت و حافظه مشاهده کنیم. محدوده 500 تا 700 دلار ، 1100 دلار و 2400 دلار برای پردازنده گرافیکی وجود دارد. شما می توانید در تعیین محدوده قیمت راحت برای تعیین GPU مورد نظر خود باقی بمانید. به عنوان مثال ، GPU توصیه شده در محدوده 1K دلار ممکن است چند سال پیش 1080TI باشد و اکنون ممکن است با قیمت مشابه 2080TI باشد. ظرفیت اضافه شده برای پردازنده های گرافیکی جدید هدر نمی رود. BERT دنباله ای از نمایش بردار را برای دنباله ای از کلمات آموزش می دهد.

Google BERT را به عنوان یکی از مهمترین به روزرسانی های الگوریتم های جستجو در درک پرس و جو کاربر قرار داد. در واقع ، ما انتظار داریم که BERT در بسیاری از برنامه های NLP از جمله پرسش و پاسخ استفاده شود.
پیش آموزش مدل پایه BERT از ابتدا گران است. یادگیری نحوه تبدیل دنباله کلمه به دنباله برداری حدود 4 روز طول می کشد تا TPU ابری به مدت چهار روز طول بکشد. خوشبختانه ، مدل های از پیش آموزش دیده وجود دارد ، بنابراین نیازی به مقابله با پیش تمرین نداریم. مرحله دوم آموزش شامل آموزش انتقال برای آموزش مدلی است که برای یک وظیفه خاص NLP هدف گذاری شده است. برای تنظیم دقیق مدل ، به مجموعه داده های دارای برچسب نیاز است.تنظیم دقیق بسیار کوتاهتر است: در عرض 1 ساعت در یک Cloud TPU ، یک Cloud TPU شامل 4 تراشه TPU است. برای یک پردازنده گرافیکی گران قیمت ، ممکن است چند ساعت طول بکشد.
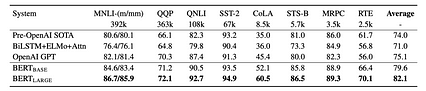
دو مدل BERT از پیش آموزش دیده وجود دارد.

جدول زیر به طور متوسط 2.7٪ بهبود در GLUE را نشان می دهد (GLUE شامل مجموعه ای از وظایف NLP) هنگام تغییر از BERT-Base به BERT-large. در DL ، این سطح بهبود با تجمع خطاها قابل توجه است. اما نیاز حافظه به احتمال زیاد آن را به 16 گیگابایت می رساند.
 منبع
منبع مدلهای آموزش دیده زیادی مانند ResNet و Inception net برای دید رایانه در دسترس هستند. برخی از مدلها ممکن است ساده تر از NLP باشند اما یادگیری انتقال معمولاً پیچیده تر از BERT است. برای من ، من مدلهای سفارشی نیز می سازم. ممکن است یک مدل GAN در برخی از مراحل بعدی من چند روز طول بکشد.
حافظه GPU چقدر است؟
من فکر می کنم 8G شروع خوبی است و 11G خوب است. اما دانستن حداقل حافظه مورد نیاز سخت است! این بستگی زیادی به مدل هایی دارد که می خواهید آموزش دهید ، نسخه های مدل و اجرای کد خارج از جعبه. در پیاده سازی NVidia ، با تجمع گرادیان و AMP ، یک واحد گرافیکی 16 گیگابایتی می تواند BERT-large را با توالی 128 کلمه ای با اندازه دسته ای موثر 256 با اجرای دسته دسته 8 و مراحل تجمع برابر 32 آموزش دهد.
اما قسمت سخت این است که ندانید از چه میزان حافظه باید خارج از حافظه جلوگیری کنید. در عوض ، به راحتی نمی توان دانست که حداقل حافظه برای دستیابی به یک سطح دقیق مشابه در هنگام استفاده از اندازه بزرگتر حافظه چقدر است. ممکن است فکر کنید این اطلاعات به طور گسترده برای پیاده سازی های رایج در دسترس است ، اما در عمل چنین نیست. در دو بخش بعدی ، مدتی را صرف پرداختن به مشکل حافظه می کنیم.
آموزش دقیق ترکیبی
وقتی کامپیوترها فقط مگابایت RAM داشتند ، مفهوم دو برابر شدن RAM با فشرده سازی حافظه زمانی در نظر گرفته شد در GPU ، ما حافظه GPU را عملا دو برابر نمی کنیم ، اما می توانیم حجم داده ها را کوچک کنیم. به طور خاص ، به جای استفاده از عملیات نقطه شناور 32 بیتی ، از ریاضی 16 بیتی استفاده می کنیم. این امر باعث کاهش رد پای حافظه و بار حافظه می شود. محاسبه نیمه دقیق نیز سریعتر خواهد بود.
در واقع ، روش دقت مختلط عملکرد را 2-4 برابر بهبود می بخشد. ذخیره واقعی حافظه کمتر از نصف خواهد بود زیرا برخی از عملیات هنوز برای دستیابی به دقت بالا نیاز به ذخیره و انجام 32 بیتی دارند. بسته به مدل ، انتظار می رود بهبود حافظه بین 50 تا 100 درصد باشد.
برای کسب اطلاعات بیشتر در مورد مفهوم دقت مختلط ، ما یک مقاله ساده داریم. خوشبختانه ، با استفاده از پلتفرم های معمول DL ، روش دقیق مخلوط را می توان در مدلهای مختلف DL با یک یا چند خط کد با استفاده از اندازه دسته ای و پارامترهای یکسان اعمال کرد. حتی بهتر ، مدل آموزش دیده در مقایسه با آموزش 32 بیتی دارای دقت مشابهی خواهد بود.
 منبع
منبع تصمیم خرید مختلط
چرا دقت مختلط بر خرید رایانه شما تأثیر می گذارد؟
معمار Nvidia Turing از هسته های Tensor برای سرعت بخشیدن به مخلوط استفاده می کند آموزش دقیق. ما می توانیم هسته های Tensor را به عنوان یک دستورالعمل ویژه اجرا کنیم که ماتریس 4 × 4 را با دقت مختلط ضرب و اضافه می کند. ماتریس های بزرگ را می توان به کاشی تقسیم کرد و در خط لوله محاسبه کرد. انویدیا تسلا V100دارای 640 هسته تنسور یعنی می تواند 640 محاسبه از این قبیل را به صورت موازی محاسبه کند. p> ممکن است خود شما مایل به پیاده سازی دقت مختلط نباشید. پیچیده تر از آنچه فکر می کنید خواهد بود. خوشبختانه ، این را می توان در بسیاری از سیستم عامل های DL با استفاده از Nvidia AMP (Automatic Mixed Precision) تحت پوشش قرار داد. اولین مورد زیر کد مورد نیاز برای TensorFlow و مورد دوم برای PyTorch با استفاده از پسوند APEX است.
 اصلاح شده از منبع
اصلاح شده از منبع اما شما باید معمار Volta یا Turing را انتخاب کنید. به عنوان مثال ، GPU 20x0 را به جای GPU 10x0 انتخاب کنید. فقط این معماران دارای هسته های Tensor هستند. com/max/426/1*BmDQ1gS0NcbFMDJ4dsn55w.jpeg "> منبع
من بحث نسبتاً زیادی را با دقت مختلط انجام می دهم زیرا می خواهم بدانید که ممکن است GPU شما دارای دکمه توربو باشد. اما شما باید آن را فشار دهید. شما به محفظه NGC TensorFlow (NVIDIA GPU-Accelerated Containers) برای TensorFlow و محفظه NGC PyTorch به علاوه کتابخانه Apex برای PyTorch احتیاج دارید.
در حال حاضر ، به انتخاب اجزای کامپیوتر باز می گردیم.
< p> تعداد GPU ها و مسیرهای PCIeیک راه خوب برای افزایش سرعت آموزش ، افزودن GPU ها به یک دستگاه است. اما چند مسئله وجود دارد که باید به آنها توجه کنید. برای پردازنده های گرافیکی دوگانه و چندگانه ، با وب سایت های فروشنده رایانه مشورت کنید تا ببینید آیا به منبع تغذیه بیشتری نیاز دارید (البته یک اسلات اضافی PCIe برای کارت گرافیک). در برخی شرایط ، ممکن است شما را به سطح بعدی کامپیوترها سوق دهد. فروشنده رایانه شخصی ممکن است از شما برای ارتقاء CPU و سایر قطعات درخواست کند. این دستگاه در نهایت ممکن است 2 هزار دلار دیگر بدون احتساب کارت GPU جدید اضافه کند. اما این بستگی به پردازنده های گرافیکی دارد. یک فروشنده رایانه شخصی ممکن است دو پردازنده گرافیکی 2080 با یک دستگاه بازی سطح متوسط ارائه دهد در حالی که فقط GPU های دوگانه 2080TI با یک دستگاه بازی درجه یک ارائه می دهد.
یکی از گرانترین ارتقاء مربوط به CPU است. مردم اغلب پیشنهاد می کنند که به تعداد خطوط PCIe توجه ویژه ای داشته باشید. کارت GPU باید از خطوط PCIe 16x یا 8x به CPU (مانند خطوط 16 یا بزرگراه 8 خط) استفاده کند. از لحاظ تئوری ، اگر 2 کارت GPU دارید ، می خواهید 32 خط CPU PCIe به 2 GPU اختصاص داده شود. این امر هرگونه تنگنای نظری غیر ضروری را به حداقل می رساند.
من شخصاً این ادعا را اذیت می کنم. ما نباید تأثیر عملکرد را بدون زمینه مناسب اندازه گیری کنیم. س questionال اصلی باید این باشد که میانگین حجم بار معمولی چقدر است؟ در واقع ، بسیاری از معیارهای برنامه های بازی تنها در صورتی که از 8 خط در GPU استفاده شود ، 1-2 درصد افت عملکرد را نشان می دهد. سایر معیارهای DL ممکن است تخریب بسیار مشابهی را نشان دهند.
پیگیری 16 خط برای هر پردازنده گرافیکی با قیمتی همراه است. دستگاه های بازی سطح متوسط معمولاً دارای پردازنده ای با 16 خط پردازنده PCIe هستند.
 منبع
منبع می توانید از پردازنده های سطح بالای اینتل مانند سری X استفاده کنید. آنها 44 باند دارند. تراشه های پایانی AMD دارای 60 خط PCIe هستند. اما هر دو نوع تراشه هزینه قابل توجهی بیشتری دارند. علاوه بر این ، حتی اگر اسلات PCI-e x16 دارید ، ممکن است آنها با سرعت x16 کار نکنند. شما نیاز به مادربرد و چیپست طراحی شده برای پشتیبانی از 16x داریدسرعت برای آن شکاف نیز در واقع ، فروشندگان رایانه های شخصی تنها می توانند این قابلیت ها را به دستگاه های بازی برتر خود با قیمت پایه 3K دلار ارائه دهند. همانطور که در زیر در کنترل پنل Nvidia نشان داده شده است ، نوع گذرگاه کارت GPU PCIe x16 است اما پیوند PCIe فقط در x8 عمل می کند.
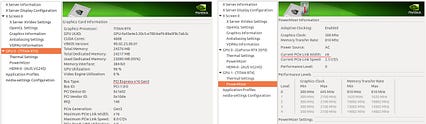
هنگامی که دو دستگاه 2080TI را در دستگاه قرار می دهید ، بسیاری از فروشندگان رایانه معتقدند که به CPU قوی تری با خطوط PCIe بیشتر نیاز دارید. این بخشی از دلیل افزایش ناگهانی قیمت سیستم دوگانه 2080TI است.
از آنجا که ممکن است با توصیه های دیگران مغایرت داشته باشم ، اگر تصمیم دارید آن را گسترده تر کنید ، کمی وقت خود را صرف توضیح خطوط PCIe می کنم. اول ، خطوط CPU شما باید به اندازه کافی برای چندین GPU شما گسترده باشد. اما آن را با خطوط PCIe در چیپست مادربرد اشتباه نگیرید. خطوط CPU معمولاً برای اتصال CPU به کارت های گرافیک است. گاهی اوقات ، می تواند CPU را در دسترسی به RAM دور کند. سایر دستگاهها ممکن است در چیپست به خط PCIe متصل شوند اما تمام ترافیک از طریق DMI 3.0 با حداکثر توان 3.93 گیگابایت بر ثانیه هدایت می شود. در زیر خطوط پردازنده 44x در بالا سمت چپ برای پردازنده سری X و 24 PCIe از چیپست Intel X229 در زیر آن نشان داده شده است.
 منبع
منبع همانطور که گفته شد ، برای طراحی با سرعت x16 نیز نیاز به درگاه PCIe مادربرد دارید. بسیاری از مشخصات ممکن است به شما نشان دهند که دو اسلات x16 PCIe دارند. اما همانطور که در زیر نشان داده شده است ، این بدان معنا نیست که آنها با سرعت x16 کار می کنند. در صورت شک و تردید با فروشنده رایانه خود مشورت کنید.
 منبع < p> بیایید خلاصه کنیم. هر GPU باید حداقل 8 خط PCIe CPU را از بین ببرد. این که آیا شما به خطوط بیشتری نیاز دارید قابل بحث است. مقیاس های عملکردی تقریباً با 1-4 GPU برای اکثر مدل های DL نزدیک به خطی است. ما می توانیم NVLink را بین GPU NVidia اضافه کنیم تا ارتباط مستقیم بین GPU ها تسهیل شود. اما آماده پرداخت هزینه اضافی به استثنای کارت های GPU هنگام پرش به 2 یا 4 CPU باشید.
منبع < p> بیایید خلاصه کنیم. هر GPU باید حداقل 8 خط PCIe CPU را از بین ببرد. این که آیا شما به خطوط بیشتری نیاز دارید قابل بحث است. مقیاس های عملکردی تقریباً با 1-4 GPU برای اکثر مدل های DL نزدیک به خطی است. ما می توانیم NVLink را بین GPU NVidia اضافه کنیم تا ارتباط مستقیم بین GPU ها تسهیل شود. اما آماده پرداخت هزینه اضافی به استثنای کارت های GPU هنگام پرش به 2 یا 4 CPU باشید. CPU & Memory
CPU عمدتا برای پیش پردازش داده ها و افزایش داده ها در طول آموزش است. بنابراین یک پردازنده معقول تهیه کنید اما انتظار کمتری برای برنامه های کاربردی شدید GPU داشته باشید. من CPU های برتر را دریافت نخواهم کرد. در عوض ، من این پول را در تنگناهای دیگر ، به ویژه GPU ، دوباره سرمایه گذاری می کنم. من معیارهای CPU را بررسی می کنم تا هزینه ارتقا را توجیه کند. باز هم ، برنامه های کاربردی مورد نظر شما باید به GPU متصل باشند.
برای حافظه ، من با 32 گیگابایت شروع می کنم. اما اطمینان حاصل کنید که در صورت لزوم جا دارید تا بعداً تا 64 گیگابایت افزایش دهید. اما سازگاری و ارتقاء حافظه بسته به فروشندگان رایانه شما می تواند بسیار مشکل باشد. تکالیف خود را با دقت انجام دهید.
برای 3-4 GPU ، ممکن است به CPU قوی تر و حافظه بیشتر نیاز داشته باشید. اما پردازنده گرافیکی دوگانه نیازی به دو برابر شدن پردازنده یا حافظه ندارد. حتی ممکن است روی پردازنده و حافظه برای سیستم GPU دوگانه تأثیر نگذارد. منابع زیادی در یک آزمایش مشترک هستند. شما به احتمال زیاد CPU اضافی برای اداره GPU های دوگانه دارید. برای چندین پردازنده گرافیکی ، پردازنده های AMD به دلیل قیمت و تعداد پردازنده می توانند جذاب باشنداگر بیش از 2 GPU انجام می دهید ، خطوط PCIe.
فضای دیسک
مجموعه داده ImageNet حدود 138 گیگابایت با فرمت tar است. برای بارگیری و استخراج فایل حدود 300 گیگابایت نیاز است. مجموعه داده BERT برای بارگیری و آماده سازی داده 600 گیگابایت طول می کشد. یک SSD 1 ترابایتی M.2 PCIe NVMe SSD یک شروع خوب با یک درایو ارزان تر 2 تا 3 ترابایتی ارزان تر است. اگر قیمت SSD کاهش یابد ، ممکن است حتی یک درایو SSD بزرگتر بخواهید.
منبع تغذیه
رایانه ای با پردازنده گرافیکی پیشرفته ممکن است توسط فروشنده GPU برای منبع تغذیه 650 وات (لطفاً این اطلاعات را برای GPU خود تأیید کنید.) این یکی از عواملی است که ممکن است لازم باشد در مورد چند GPU دقت کنید. در صورت نیاز به برق بیشتر ، ابزار پیکربندی در وب سایت خرید رایانه ممکن است به شما هشدار دهد. اما اگر کارت دوم را جداگانه خریداری کنید ، باید بررسی کنید که آیا منبع تغذیه برای کارت دوم قدرت کافی دارد. طراحی سیستم با 3 یا بیشتر GPU عملکرد GPU به نیازهای حرارتی و قدرت حساس است. هنگامی که GPU بیش از حد گرم می شود ، عمداً کند می شود. برای 3 یا چند GPU که به هم نزدیک می شوند ، ممکن است بین کارت های GPU فاصله ای وجود نداشته باشد.
 منبع
منبع پردازنده گرافیکی با کولر دمنده برای این پیکربندی توصیه می شود تا هوای گرم را به طرف و بیرون محفظه فشار دهد. اما GPU دمنده معمولاً پر سر و صدا تر و گرمتر است. یک پردازنده گرافیکی در فضای باز ساکت تر و گرمتر است اما اگر کارت ها به هم نزدیک باشند کارآمد نخواهد بود.
OS
برای DL ، لینوکس معمولاً اولین پلت فرم نرم افزار است رهایی. برای دستگاه رومیزی ، از اوبونتو استفاده می کنم. مراحل نصب حدود 15 دقیقه به طول می انجامد ، اما برای ساعت ها عیب یابی آماده باشید.
اجرای آزمایشها با GPU های متعدد
افراد برای تسریع آموزش آزمایش ، کارتهای یکسان اضافه می کنند. بسته به بستر DL ، این را می توان بدون کد نویسی یا کمی انجام داد. اما ، برای من ، من همچنین سیستمی می خواهم که بتواند چندین آزمایش را همزمان انجام دهد: یکی برای آموزش طولانی مدت و دیگری برای آزمایش های کوتاه تر. برخی از افراد برای جستجوی هایپر پارامترها از کارت های متعدد استفاده می کنند. هر آزمایش بر روی یک کارت جداگانه با پارامترهای مختلف اجرا می شود.
Buy v.s. ساخت سفارشی
اگر دستگاه خود را می سازید ، باید مطمئن شوید که مادربرد شما با سرعت خاصی که برای هر شکاف PCIe نیاز دارید طراحی شده است. همچنین مطمئن شوید منبع تغذیه شما دارای قدرت کافی است. شما می توانید یک سیستم "سردتر" را به معنای واقعی کلمه طراحی کنید. من از دیدگاه DL به شما اطلاعات می دهم. بهتر است این معیارها را به افراد متخصص در پیکربندی ماشین سفارشی منتقل کنید. به طور خاص ، ابتدا ، باید انتخاب GPU های خود را انتخاب کنید. سپس ، می توانید از آنها برای کل تنظیمات رایانه ای که در اطراف GPU ها ایجاد شده اند ، با برخی از توصیه های حافظه و ذخیره سازی که در اینجا بحث شده است ، مشاوره بگیرید. اطمینان حاصل کنید که اجزای سازگار با هم زمان می برند. PC Part Picker شروع خوبی خواهد بود. اگر به پیکربندی بسیار بهینه نیاز دارید ، مشورت با آنها احتمالاً انتخاب بهتری نسبت به افراد DL است. منپیدا کنید که آنها پیشنهادات بهتر و کاربردی تری ارائه می دهند.
یک دلیل قانع کننده برای انجام ساخت سفارشی برای چندین GPU وجود دارد. وقتی سیستم GPU دوگانه را پیکربندی می کنم ، برخی از فروشندگان سطح بعدی کامپیوترهایی را که بازده کمی برای من دارند ، فشار می دهند. و من نیازی به نصب سیستم عامل MS ندارم. پس انداز جمع می شود و شخصی 20 تا 40 درصد پس انداز می کند. من فکر می کنم اگر از GPU های دوگانه یا بیشتر استفاده کنید امکان پذیر است. با این حال ، به دلیل محدودیت زمانی ، من ترجیح کمتری برای این گزینه قائل می شوم.
انتخاب من
برای دستیابی به نیاز شخصی من ، من یک سیستم 2080TI دوگانه را پیش بینی می کنم. فروشنده رایانه شخصی چاره ای برای من باقی نمی گذارد جز انتخاب یک پردازنده AMD پیشرفته با منبع تغذیه 1500 وات. این پیکربندی حدود 2.2 هزار دلار بعلاوه 2.2 هزار دلار برای پردازنده های گرافیکی دوگانه است. این پیکربندی مرجع من خواهد بود. در حال حاضر ، من 4.4 هزار دلار طراحی دارم اما می خواهم ببینم چقدر می توانم با پول کمتر به همان طرح دست پیدا کنم.
بعد از چند هفته تلاش ، فرصتی پیش می آید که می توانم یک تایتان را به دست آورم RTX رایگان. خوشبختانه ، من طرح اصلی خود را در حال حاضر به محدوده زیر 2000 دلار نزدیک می کنم. اما من در یک فرصت احتمالی دیگر برای دو کارت 2080TI حضور داشتم. پردازنده های گرافیکی دوگانه می توانند آموزش هایی را که Titan RTX با آنها مطابقت ندارد ، سرعت بخشند. اما کارت Titan RTX یک جذابیت قوی برای من دارد. برخی از مدل های DL که روی آنها کار می کنم ، مانند BERT ، به حافظه GPU بیشتری نیاز دارند. (بعداً بدون GPU های رایگان گزینه ها را نیز مورد بحث قرار خواهم داد.)
دو پیکربندی نهایی نهایی من سیستم دوگانه 2080TI و Titan RTX است. اکنون ، من باید در مورد خصوصیات نسبی آنها در پروژه های شخصی خود تصمیم بگیرم. یک شب با آنها می خوابم و تصمیم خود را می گیرم. این یک تماس نزدیک است. در نهایت ، من Titan RTX را انتخاب می کنم. برای اجرای چندین آزمایش ، یک کارت گرافیک 2070 با حافظه 8 گیگابایت اضافه می کنم. از قضا ، این ترکیب به من امکان می دهد با یک کامپیوتر بازی سطح متوسط بمانم. در واقع ، در این سناریو هزینه کمتری از جیب من می شود.
من 100 دلار بیشتر هزینه می کنم تا CPU را به i7 9700 ارتقا دهم. من بررسی می کنم که حدود 30 تا 40 درصد معیار عملکرد بهبود یافته است. هزینه ارتقاء بعدی 350 دلار با کمتر از 10 درصد بهبود است و من کمتر اهمیت می دهم. عملکرد واقعی CPU به عوامل زیادی بستگی دارد از جمله دریچه حرارتی. برای رایانه هایی که مشکل گرم شدن بیش از حد دارند ، سرعت سریعتر CPU قابل اجرا نخواهد بود.
من سرعت حافظه را ارتقا نمی دهم (هزینه آن حدود 100 دلار است). من می توانم بدون هزینه اضافی به 2070 super ارتقا دهم اما ترجیح می دهم کارت دوم دارای مصرف برق کمتری باشد تا برخی از مشکلات احتمالی را کاهش دهد.
و این آخرین تنظیمات است.

فقط به عنوان یک مرجع ، این اطلاعات مربوط به خطوط PICe و چیپست است.
 منبع
منبع 
با این وجود ، حتی رایانه انتخاب شده دارای دو اسلات PCIe x16 است ، مادربرد فقط از سرعت x8 پشتیبانی می کند.
< p> با احتساب هزینه GPU RTX 2070 اما نه Titan RTX ، هزینه این سیستم 1،781 دلار است. من یک استراحت بزرگ دارم که سوررئال است. اما درسآموخته فکر کردن خارج از چارچوب است همیشه پیشنهادات ویژه ای در اطراف وجود دارد. بازار ثانویه را بررسی کنید. برخی از دوستان شبکه شما ممکن است بخواهند GPU های قدیمی خود را حذف کنند. آنها ممکن است یک میز اضافی روی میز داشته باشند و بخواهند مغز شما را انتخاب کنند. با نگاه کردن و کوبیدن ، ممکن است امکانات زیادی پیش بیاید. اما باز هم ، نهار رایگان وجود ندارد. این تلاش ها زمان می برد و برخی از متخصصان ممکن است در عوض برای وقت خود ارزش بیشتری قائل شوند.خطرات چیست؟
من در این فرآیند ریسک های آموزش دیده ای دارم. بنابراین وقت آن است که بررسی کنم آیا من اشتباهات بزرگی مرتکب شده ام یا خیر. اولین نگرانی من گرم شدن بیش از حد است. بنابراین من استرس هر دو GPU را همزمان تست می کنم. RTX 2070 در حدود 66 درجه سانتی گراد تثبیت می شود که من بسیار راحت هستم. Titan RTX قدرت بیشتری را می گیرد و در حدود 86 درجه سانتی گراد تثبیت می شود. هنوز زیر دمای کند شدن (91 درجه سانتی گراد) است ، اما من در آینده بیشتر به پردازنده گرافیکی Titan توجه خواهم کرد. برای آزمایش بیشتر ، من بار را از RTX 2070 بیرون می آورم و دما برای تیتان حدود 81 درجه سانتی گراد است.

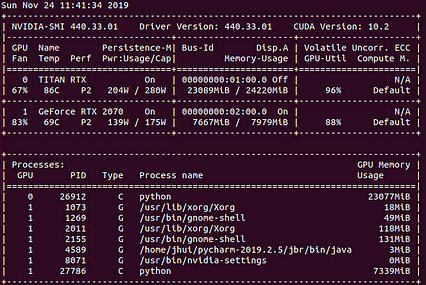
آیا می توانم بدون ضربه زدن به تنگناهای دیگر ، بار کافی به GPU ها وارد کنم؟ من همزمان دو برنامه روی GPU اجرا کردم. مدل اجرا شده بر روی Titan RTX پیچیده تر برای استفاده از GPU است. همانطور که در زیر نشان داده شده است ، تست استرس به 96٪ در Titan RTX و 88٪ در RTX 2070 می رسد. من می دانم که هنوز می توان بار بیشتری را به راحتی به GPU ها اضافه کرد. بنابراین نتیجه اولیه نشان می دهد که سیستم می تواند محدود به GPU باشد.
 < /img>
< /img> آیا تنگنای CPU دارم؟ باز هم ، استفاده از CPU فقط حدود 25 است. (مقادیر زیر را بر 8 تقسیم کنید زیرا من یک CPU 8 هسته ای دارم.) بنابراین CPU انتخابی من فضایی برای پیش پردازش بیشتر دارد.

2 ماه بعد و درسهای آموخته
2 ماه بعد ، از اعتبارات این خرید برای خرید درایوهای خارجی 4 ترابایتی استفاده می کنم با هزینه اضافی از جیب 50 دلار. در بسیاری از مجموعه داده های آموزشی DL ، علاوه بر فضای مورد نیاز برای داده ها ، فضای زیادی برای آماده سازی داده ها و ذخیره فرمت داده ای که به بهترین وجه متناسب با کد است ، صرف می شود. به عنوان مثال ، پیاده سازی BERT 600 گیگابایت فضا را با یک قطعه بزرگ اشغال می کند که برای پردازش سریعتر داده ها را در قالب TFRecord ذخیره می کند. من می توانم فضا را فقط برای قسمت داده مورد نیاز خود تمیز کنم. اما این نشان می دهد که چقدر فضای ممکن است برای یک مشکل صرف شود. اگر قیمت SSD ارزان تر است ، مطمئناً در تهیه درایو بزرگتر به شما پیشنهاد می کنم. من همچنین سعی می کنم حافظه را به 64 گیگابایت ارتقا دهم اما با مشکلات سازگاری حافظه مواجه می شوم. من قبلاً این را تأیید کرده ام ، اما به دلیل مشکلات غیرمنتظره طراحی فروشنده ، اولین تلاش برای ارتقاء حافظه من ناموفق بود. مانند همیشه ، جستجوی کمال ممکن است در زمینه مهندسی ممکن نباشد. فقط هزینه آن را کمتر کنید این مسئله غیرمنتظره به احتمال زیاد 100 دلار اضافی به من اضافه می کند. اما این مسئله برای من مهم نیست حتی اگر من ارتقا ندارم.
یک دستگاه برد 1700 دلار
Iامیدوارم اطلاعات اینجا بتواند آن را به انتخاب های کمتری برای شما محدود کند. اما برای انصاف ، بیایید ریاضی را برای یک سیستم حدود 1700 دلار بسازیم. از سال 2019 ، می توانید یک رایانه با قیمت 1700 دلار با یک پردازنده گرافیکی فوق العاده Nvidia 2070 با 8 گیگابایت GPU و 32 گیگابایت رم میزبان تهیه کنید. این پردازنده شامل نسل نهم i7 ، 1 ترابایت M.2 PCIe NVMe SSD و درایو 1 ترابایتی SATA خواهد بود. برای ارتقاء به 2080 super یا 2080TI به ترتیب می توانید 150 یا 600 دلار اضافه کنید. عملکرد را به ترتیب 50 تا 100 درصد افزایش می دهد. این پردازنده های گرافیکی کارهای بسیار خوبی را برای شما انجام خواهند داد. اگر به قدرت بیشتر GPU نیاز است ، GPU های بیشتری اضافه کنید. اما هزینه شما به صورت غیر خطی افزایش می یابد زیرا شما به یک کامپیوتر قوی تر نیاز دارید. اگر به حافظه GPU بیشتری نیاز دارید زیرا آموزش شما خارج از حافظه است ، باید برای گفتن Titan RTX حرکت کنید.
با این حال ، قطعات رایانه به احتمال زیاد در طول زمان کاهش می یابد. با کاهش قیمت ، می توانید با همان بودجه هدف اما برای GPU بهتر بمانید. ظرفیت اضافی هدر نمی رود. به عنوان مثال ، یک ماه و نیم پس از خرید من ، می توانید سیستم را با درایو SSD 2 ترابایتی با کارت گرافیک فوق العاده Nvidia 2080 با همان قیمت 1700 دلار ارتقا دهید.
اعتبارات و منابع
GPU مقایسه عملکرد و هزینه: کدام GPU (ها) را برای یادگیری عمیق دریافت کنید: تجربه و توصیه من برای استفاده از GPU ها در یادگیری عمیق
جعبه یادگیری عمیق عالی 1700 دلاری: مونتاژ ، تنظیمات و معیارها
< p> معیار مقیاس پذیری: TensorFlow Performance with 1-4 GPUs - RTX Titan، 2080Ti، 2080، 2070، GTX 1660Ti، 1070، 1080Ti، and Titan Vانتخاب قطعات کامپیوتر: PCPartPicker
آموزش دقیق ترکیبی
آموزش دقیق مخلوط شبکه های عصبی عمیق
آموزش با دقت ترکیبی
سری ویدئوها: تکنیک های آموزش مختلط با استفاده از هسته های تنسوری برای یادگیری عمیق
NVIDIA Apex: ابزارهایی برای آموزش آسان ترکیبی دقیق در PyTorch
معماری سیستم Cloud TPU
پیاده سازی Google BERT


























