یادگیری بینایی رایانه ای
یادگیری بینایی رایانه ای
اخیراً من در حال مطالعه و آزمایش زیاد با دید رایانه هستم ، در اینجا مقدمه ای برای یادگیری و استفاده جالب در آن حوزه آمده است.
 تقسیم بندی تصویر برای رانندگی خودران
تقسیم بندی تصویر برای رانندگی خودران بینایی رایانه در سالهای اخیر بسیار پیشرفت کرده است. اینها موضوعاتی است که در اینجا به آنها اشاره می کنم:
فناوری ها:
برنامه های کاربردی:
افرادی که باید دنبال شوند:
زمینه های مرتبط:
مراجعه کنید. تشخیص چهره
 تشخیص چهره در مورد قرار دادن کادر در اطراف صورت
تشخیص چهره در مورد قرار دادن کادر در اطراف صورت تشخیص چهره وظیفه تشخیص چهره است. الگوریتم های مختلفی برای انجام این کار وجود دارد. >
طبقه بندی کننده هاار
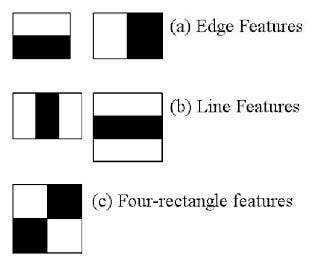 ویژگی های haar
ویژگی های haar آنها این روش قدیمی بینایی رایانه ای است که از سال 2000 در opencv وجود دارد. در این مقاله http://wearables.cc.gatech.edu/paper_of_week/viola01rapid.pdf.
این یک مدل یادگیری ماشین با ویژگی هایی که به طور خاص برای تشخیص شی انتخاب شده اند. طبقه بندی کننده های Haar سریع هستند اما دقت پایینی دارند.
توضیحات بیشتر و مثال نحوه استفاده از آن را در https://docs.opencv.org/3.4.3/d7/d8b/tutorial_py_face_detection ببینید. html
HOG: هیستوگرام گرادیانهای جهت دار
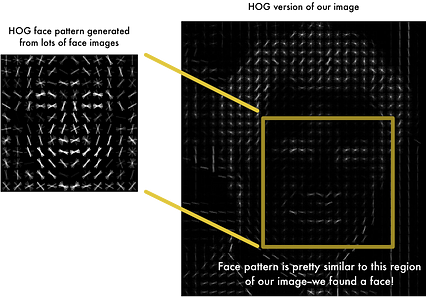 هیستوگرام گرادیان های جهت دار
هیستوگرام گرادیان های جهت دار HOG یک روش جدیدتر برای ایجاد ویژگی برای تشخیص شی است: از سال 2005 شروع به کار کرده است. این بر اساس محاسبه شیب بر روی پیکسل تصاویر شما است. این ویژگی ها سپس به الگوریتم یادگیری ماشین ، به عنوان مثال SVM ، تغذیه می شوند. دقت بهتری نسبت به طبقه بندی کننده haar دارد.
پیاده سازی آن در dlib است. که در face_recognition (https://github.com/ageitgey/face_recognition) lib.
MTCNN
روش جدیدی با استفاده از تنوع در CNN ها برای تشخیص تصاویر است. دقت بهتر اما کمی کندتر. https://kpzhang93.github.io/MTCNN_face_detection_alignment/index.html
MobileNet
بهترین و سریعترین روش این روزها برای تشخیص چهره را ببینید. بر اساس معماری کلی شبکه تلفن همراه https://arxiv.org/abs/1704.04861
تشخیص شی
 تشخیص اشیاء در انواع مختلف اشیاء
تشخیص اشیاء در انواع مختلف اشیاء با استفاده از روشهای مشابه تشخیص چهره می توان به تشخیص شی اکتفا کرد.
در اینجا 2 مقاله وجود دارد که روشهای اخیر برای دستیابی به آن را ارائه می دهد. این روش ها حتی گاهی اوقات کلاس اشیا را نیز ارائه می دهند (دستیابی به تشخیص شی): r-fcn
تشخیص شی
تشخیص شی مشکل کلی طبقه بندی شیء به دسته ها (مانند گربه ، سگ ، ...)
شبکه عصبی عمیق بر اساس برای دستیابی به نتایج عالی در این کار ، از کانولوشن استفاده شده است.
کنفرانس ILSVR میزبان مسابقه ای در ImageNet (http://www.image-net.org/پایگاه داده ای از بسیاری از تصاویر موجود در اشیاء) برچسب هایی مانند گربه ، سگ ، ..)
شبکه های عصبی موفق تر و بیشتر از لایه استفاده می کنند.

معماری ResNet بهترین طبقه بندی شی تا به امروز است.
 معماری Resnet
معماری Resnet برای آموزش صحیح آن ، استفاده از میلیون ها تصویر مورد نیاز است ، و حتی با ده ها مورد نیاز به زمان زیادی نیاز دارد. GPU های گران قیمت.
به همین دلیل است که روشهایی که نیازی به آموزش مجدد در چنین مجموعه های داده بزرگ ندارند ، بسیار مفید هستند. یادگیری انتقال و جاسازی از این قبیل روشها است.
مدلهای از پیش آماده برای بازنشانی مجدد در https://github.com/tensorflow/tensor2tensor#image-classification
تشخیص چهره
موجود است.تشخیص چهره این است که بفهمید چه کسی یک چهره است.
روشهای تاریخی
روش تاریخی برای حل این کار ، استفاده از مهندسی ویژگی با یادگیری ماشین استاندارد (برای مثال svm) یا استفاده از روشهای یادگیری عمیق برای تشخیص اشیاء. در عمل آن داده ها همیشه در دسترس نیستند. این روش روشی را برای تشخیص چهره ها ارائه می دهد که نمونه های زیادی از چهره برای هر فرد در نظر گرفته نشده است. .edu/lfw/) تعداد زیادی از چهره ها.
سپس معماری بینایی رایانه ای موجود مانند آغاز (یا بازنشانی مجدد) را در نظر بگیرید و سپس آخرین لایه NN تشخیص شیء را با لایه ای محاسبه کنید جاسازی صورت.
برای هر فرد در مجموعه داده (نمونه منفی ، نمونه مثبت ، نمونه مثبت دوم) سه چهره (با استفاده از روش های اکتشافی) انتخاب شده و به شبکه عصبی تغذیه می شوند. که 3 جاسازی تولید می کند. در این 3 جاسازی تلفات سه گانه محاسبه می شود که فاصله بین نمونه مثبت و هر نمونه مثبت دیگر را به حداقل می رساند و فاصله بین نمونه موقعیتی و هر نمونه منفی دیگر را حداکثر می کند.
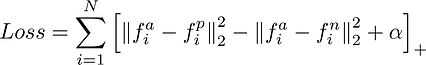 از دست دادن سه قلو
از دست دادن سه قلو 
نتیجه نهایی این است که هر صورت (حتی چهره هایی که در مجموعه آموزشی اصلی وجود ندارند) اکنون می تواند به صورت یک جاسازی (بردار 128 عددی) که بزرگ است نشان داده شود. فاصله از جاسازی چهره افراد دیگر.
این جاسازی ها را می توان با هر مدل یادگیری ماشین (حتی مدلهای ساده مانند knn) برای تشخیص افراد استفاده کرد.
چیزی که در مورد جاسازی صورت و صورت بسیار جالب است که با استفاده از آن می توانید افراد را فقط با چند عکس از آنها یا حتی یک عکس تشخیص دهید.
مشاهده آن lib که آن را اجرا می کند: /face_recognition < /p>
این پیاده سازی tensorflow آن است: https://github.com/davidsandberg/facenet
این یک برنامه جالب از ایده های پشت این خط تشخیص چهره است تا در عوض چهره خرس ها را تشخیص دهد: https://hypraptive.github.io/2017/01/21/facenet-for-bears.html
انتقال یادگیری
 به سرعت یک شبکه عصبی دقیق را در یک مجموعه داده سفارشی مجددا آموزش دهید > داده ها.
به سرعت یک شبکه عصبی دقیق را در یک مجموعه داده سفارشی مجددا آموزش دهید > داده ها. بینایی رایانه ای بسیار محاسباتی است (چندین هفته آموزش روی gpu چندگانه) و نیاز بهداده های زیاد برای برطرف کردن آن ، ما قبلاً در مورد محاسبه جاسازی عمومی برای چهره صحبت کردیم. راه دیگر برای انجام این کار این است که از یک شبکه موجود استفاده کرده و فقط چند لایه از آن را در مجموعه داده دیگری آموزش دهید.
در اینجا یک آموزش برای آن وجود دارد: آموزش codelab به شما پیشنهاد می کند که یک مدل اولیه را آموزش دهید تا کلاسهای گل ناشناخته را آموزش دهید. لایه ای برای آموزش مجدد هنگام انجام آموزش انتقال.
تقسیم بندی تصویر
 تقسیم بندی تصویر برای رانندگی مستقل
تقسیم بندی تصویر برای رانندگی مستقل تقسیم بندی تصویر یک کار جدید قابل توجه است که در سالهای اخیر امکان پذیر شده است. این شامل شناسایی هر پیکسل یک تصویر است.
این کار مربوط به تشخیص شی است. یک الگوریتم برای دستیابی به آن ماسک r-cnn است ، برای جزئیات بیشتر به این مقاله مراجعه کنید https://medium.com/@jonathan_hui/image-segmentation-with-mask-r-cnn-ebe6d793272
GAN < /h1>  مقیاس بزرگ GAN
مقیاس بزرگ GAN
تولیدکننده شبکه های مزاحم ، معرفی شده توسط ian goodfellow ، یک معماری شبکه عصبی در 2 قسمت است: یک تشخیص دهنده و یک مولد. >
وزن ژنراتور در حین یادگیری به گونه ای تنظیم می شود که تصاویری را ایجاد کند که تشخیص دهنده نمی تواند از تصاویر واقعی آن کلاس تشخیص دهد.
< p> در اینجا نمونه ای از تصاویر تهیه شده توسط بزرگترین GAN است https://arxiv.org/abs/1809.11096پیاده سازی GAN در keras را در https://github.com/eriklindernoren/مشاهده کنید Keras-GAN
سخت افزاری برای بینایی کامپیوتر

برای آموزش مدل های بزرگ ، منابع زیادی مورد نیاز است. برای دستیابی به آن دو راه وجود دارد. اولین مورد استفاده از خدمات ابری ، مانند google cloud یا aws است. راه دوم این است که خودتان یک کامپیوتر با GPU بسازید.
با حداقل 1000 دلار می توانید یک ماشین مناسب برای آموزش مدل های یادگیری عمیق بسازید.
این مطلب را با جزئیات بیشتر بخوانید. در https://hypraptive.github.io/2017/02/13/dl-computer-build.html
دید در UI
 داشبورد چهره selfphotos
داشبورد چهره selfphotos Ownphotos یک رابط کاربری شگفت انگیز است که به شما امکان می دهد عکس های خود را وارد کرده و به طور خودکار جاسازی چهره را محاسبه کنید ، تشخیص شی و تشخیص چهره ها.
از موارد زیر استفاده می کند:
برنامه های کاربردی
< img src = "https://cdn-images-1.medium.com/max/426/0*sT9nWAypwSttkNDC.jpg"> پاسخ به سualالات بصریبینایی کامپیوتر کاربردهای زیادی دارد:
< uli> سازمان عکسهای شخصینتیجه گیری
همانطور که در اینجا دیدیم ، بسیاری از روشها و برنامه های جالب جدید ناشی از موفقیت آنها وجود دارد.
من فکر می کنم آنچه در هوش مصنوعی به طور کلی و در بینش به طور خاص جالب ترین است ، یادگیری الگوریتم قابل استفاده مجدد است تا بتوان از این روش ها برای کارهای بیشتر و بیشتر بدون نیاز به قدرت پردازش و داده های زیاد استفاده کرد:
< uli> انتقال یادگیری: امکان استفاده مجدد از شبکه های عصبی بزرگ از پیش آماده شده

























